
효율적인 쿠버네티스 설계 – 노드 용량 산정
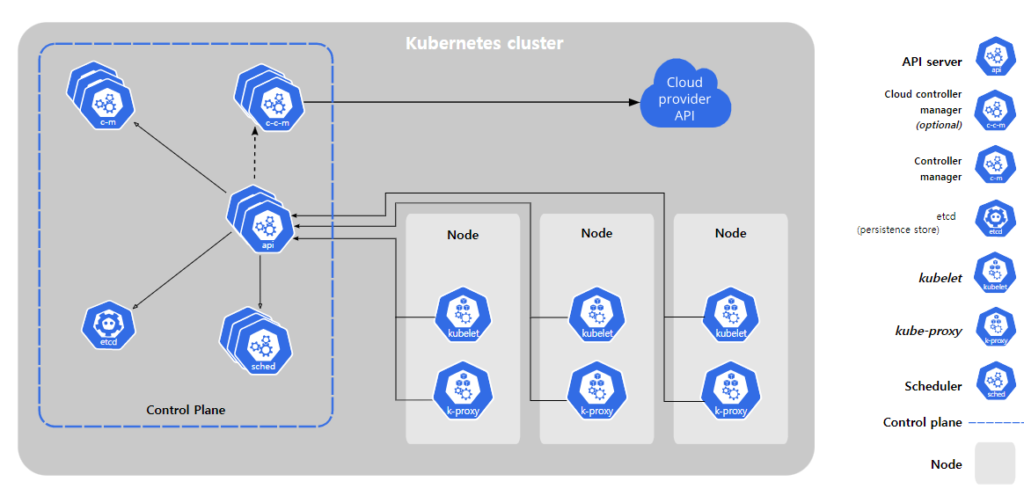 그렇다면, Pod는 노드의 모든 리소스를 사용할 수 있을까요?
그렇다면, Pod는 노드의 모든 리소스를 사용할 수 있을까요?
📒 쿠버네티스 클러스터 노드에 리소스가 할당되는 방식
운영 체제와 kubelet 에도 사용 가능한 리소스를 다음과 같이 나눌 수 있습니다.

- – System-reserved : SSH, systemd 등과 같은 운영 체제 및 시스템 데몬을 실행하는 데 필요한 리소스
- – Kube-reserved : Kubelet, 컨테이너 런타임, Node problem detector 등과 같은 Kubernetes 에이전트를 실행하는 데 필요한 리소스
- – Eviction threshold : 노드의 메모리 가용성이 예약된 값보다 낮아지면 노드 리소스를 회수하기 위해 파드를 중단하는 절차
- – Allocatable : Pod 를 위해 할당 가능한 리소스
각 노드의 Kubelet 은 컨트롤 플랜의 API 서버에게 주기적으로 노드와 Pod 의 상태를 전달하는 역할을 하며 Pod 가 늘어날 수록 kube-reserved CPU/Memory 리소스도 늘어납니다. 또한 운영체제의 데몬 리소스도 무시할 수 없습니다.
이러한 노드의 총 리소스와 할당 가능한 리소스 간에 불일치가 발생할 수 있기 때문에 클라우드 서비스 공급업체에서는 관리형 쿠버네티스 서비스의 노드 성능과 기능 유지를 위해 각 노드에 CPU와 Memory 유형으로 리소스를 예약하고 있습니다.
📒 Managed Kubernetes Service 예약 리소스 정책
| 관리형 쿠버네티스 서비스 | CPU | Memory |
| GKE |
|
|
| EKS | Reserved memory = 255MiB + 11MiB * MAX_POD_PER_INSTANCE | |
| AKS | CPU cores on host / Kube-reserved (millicores)
|
AKS 1.29 이후
둘 중 더 낮은 값으로 선택
AKS 1.29 이전
|
AWS EKS 의 MAX_POD_PER_INSTANCE는 각 인스턴스 유형마다 실행할 수 있는 최대 Pod 수를 정하고 있습니다.
예를 들어 m5.large인스턴스는 Pod는 29개만 실행할 수 있지만 m5.4xlarge 는 234개까지 실행할 수 있습니다.(각 EC2 인스턴스에 제한된 수의 IP 주소만 할당, Prefix 설정으으로 제한 수를 변경도 가능함.) 이를 위해 AWS는 인스턴스당 최대Pod 수를 추정하기 위해 실행할 수 있는 스크립트를 제공합니다.
예시, 만약 2 vCPU 8GiB 인스턴스로 노드를 구성한 경우에 Pod 를 위해 할당 가능한 리소스를 계산해보겠습니다.
| 관리형 쿠버네티스 서비스 | 예약된 리소스 | 가용한 리소스 |
| GKE
n1-standard-2(2 vCPU 7.5GiB) |
Reserved CPU = 0.06 * 1 (first core) + 0.01 * 1 (second core)
Reserved Memory = 0.25 * 4 (first 4GB) + 0.2 * 3.5 (remaining 3.5GB) Eviction threshold = 100MB
|
1930m = 2 vCPU – 70m(예약된 리소스)
5.6GiB = 7.5GiB – 1.7GiB(예약된 리소스) |
| EKS
m5.large(2 vCPU 8GiB 110 pods) |
Reserved CPU = 0.06 * 1 (first core) + 0.01 * 1 (second core)
Reserved memory (110 pods) = 255Mi + 11MiB * 110 Eviction threshold = 100MB |
1930m = 2 vCPU – 70m(예약된 리소스)
6.5GiB = 8GiB – 1.5GiB(예약된 리소스) |
| AKS
D2v3(2 vCPU 8GiB) |
Reserved CPU = 100 m
Reserved Memory = 0.25 * 8GiB Eviction threshold = 100MB |
1800 m = 2 vCPU – 100m(예약된 리소스)
5.9GiB = 8GiB – 2.1GiB(예약된 리소스) |
시나리오 결과, 노드 전체 메모리에서 75 %만 워크로드를 실행하는 데 사용될 수 있는 것으로 보입니다. 그리고 이 비율은 큰 노드일 수록 CPU/Memory 예약 리소스 비율이 낮아지게 됩니다. 또 다른 시나리오로 고가용성을 위해 작은 노드로 클러스터를 구성하게 되면 오히려 예약된 리소스로 인해 오히려 효율이 떨어질 수 있습니다.
예시에서는 System resource(최소 v CPU 100m / Memory 100MiB)를 제외하였기 때문에 실운영 환경에서는 보다 보수적으로 산정할 필요가 있습니다. 또한 DaemonSet이나 Agent 사용량도 고려해야합니다.
📒 구축형 쿠버네티스 예약 리소스 정책
관리형 쿠버네티스 서비스 외에도 자체 관리형 쿠버네티스에서는 어떻게 리소스 정책을 가지고 있을까요?
쿠버네티스에는 기본 설정된 예약 리소스는 없지만 커뮤니티에서 권장하는 예약 리소스 정책이 있습니다. 정책은 GKE 와 동일합니다.
CPU |
Memory |
|
| 구축형 쿠버네티스 |
|
|
위 정책은 권장 값이며, 쿠버네티스는 다양한 클라우드 인프라 환경에서 구축 가능하기 때문에 HCI 나 하이퍼바이저등 각 인프라 환경에 따라 예약 리소스 정책은 설정되어야합니다. 하이퍼바이저마다 성능을 보장하는 CPU overcommit 수준도 고려사항 중 하나입니다.

4core/8GiB 노드의 예약 리소스
📒 요약
클러스터 노드는 CPU와 Memory 리소스가 더 클수록 효율성 측면에서 좋다는 결론을 내릴 수 있습니다.
이번 글에서는 단순히 노드 크기 산정에 대해서 고민했지만 실제 운영 환경에서는 탄력성과 복원력이 필요하기 때문에 클러스터 설계에서 노드 크기 산정은 더 어려운 문제가 될 수 있습니다.
다음 글에서는 탄력성과 복원력을 고려한 클러스터 설계에 대해 알아보겠습니다.
🔗 참고 자료
- https://cloud.google.com/kubernetes-engine/docs/concepts/plan-node-sizes?hl=ko#memory_and_cpu_reservations
- https://github.com/awslabs/amazon-eks-ami/blob/d87c6c49638216907cbd6630b6cadfd4825aed20/templates/al2/runtime/bootstrap.sh#L517
- https://learn.microsoft.com/en-us/azure/aks/concepts-clusters-workloads#resource-reservations
- https://kubernetes.io/docs/tasks/administer-cluster/reserve-compute-resources/#node-allocatable
- https://learnk8s.io/allocatable-resources



